
1.概述
1.1.定义
英文名:Analytical Data Warehouse for Big Data。
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供 Hadoop 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,
最初由eBay Inc.开发并贡献至开源社区。它能在亚秒内查询巨大的 Hive 表。
1.2.架构
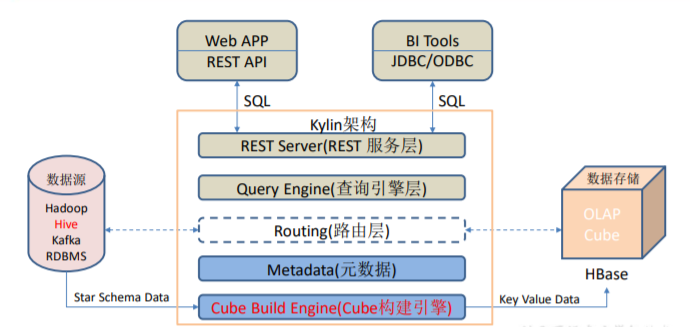
1.2.1.Rest Server
是一套面向应用程序开发的入口点,旨在实现针对 Kylin 平台的应用开发 工作。 此类应用程序可以提供查询、获取结果、触发 cube 构建任务、获取元数据以及获取 用户权限等等。另外可以通过 Restful 接口实现 SQL 查询。
1.2.2 查询引擎
当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。它随后会与系统中的其它 组件进行交互,从而向用户返回对应的结果。
1.2.3 路由层
当 Kylin 不能执行的查询引导去 Hive 中继续执行。这个一般关闭。因为打开会导致查询时间不稳定,查询kylin快,查询hive慢。
1.2.4 元数据管理
Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存 在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 cube 元数据。其它全部组件的 正常运作都需以元数据管理工具为基础。 Kylin 的元数据存储在 hbase 中。
1.2.5 构建引擎
目的在于处理所有离线任务,其中包括 shell 脚本、Java API 以及 Map Reduce 任务等等。
1.3.kylin特点
1)标准 SQL 接口:Kylin 是以标准的 SQL 作为对外服务的接口。
2)支持超大数据集:有千亿记录秒级查询的案例。
3)亚秒级响应:Kylin通过预计算,将很多复杂的计算,比如连接、聚合,在离线的预计算过程中就已经完成,大大降低了查询时刻所需的计算量,
提高了响应速度。
4)可伸缩性和高吞吐率:单节点 Kylin 可实现每秒 70 个查询,还可以搭建 Kylin 的集群。
5)BI 工具集成:Kylin 可以与现有的 BI 工具集成,具体包括如下内容。ODBC:与 Tableau、Excel、PowerBI 等工具。
集成JDBC:与 Saiku、BIRT 等 Java 工具。集成RestAPI:与 JavaScript、Web 网页集成。
2.kylin环境搭建
2.1.搭建步骤
安装 Kylin 前需先部署好 Hadoop、Hive、Zookeeper、Hbase、Spark,并且需要在/etc/profile中配置对应环境变量。
2.2.kylin启动
(1)启动 Kylin 之前,需先启动 Hadoop(hdfs,yarn,jobhistoryserver)、Zookeeper、Hbase
(2)启动 Kylin:$ bin/kylin.sh start 在 http://hadoop102:7070/kylin 查看 Web 页面,用户名为:ADMIN,密码为:KYLIN
(3)关闭 Kylin:$ bin/kylin.sh stop
3.kylin快速入门
3.1.使用入门
参考官网:
(1)Web界面 http://kylin.apache.org/cn/docs30/tutorial/web.html
(2)cube创建 http://kylin.apache.org/cn/docs30/tutorial/create_cube.html
(3)cube构建和JOB监控 http://kylin.apache.org/cn/docs30/tutorial/cube_build_job.html
3.2 使用页面构建cube
3.2.1 创建model
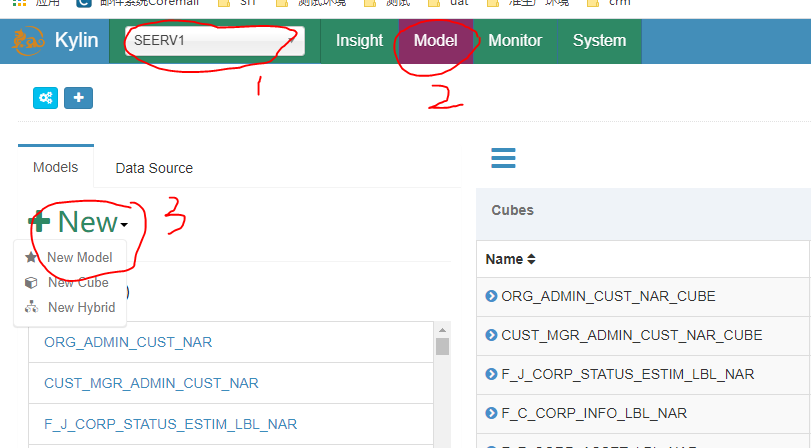
3.2.1.1 new model
选择project->点击model->点击new->点击new model
3.2.1.2 填写model Info
 输入名称和描述
输入名称和描述
3.2.1.3 填写data model
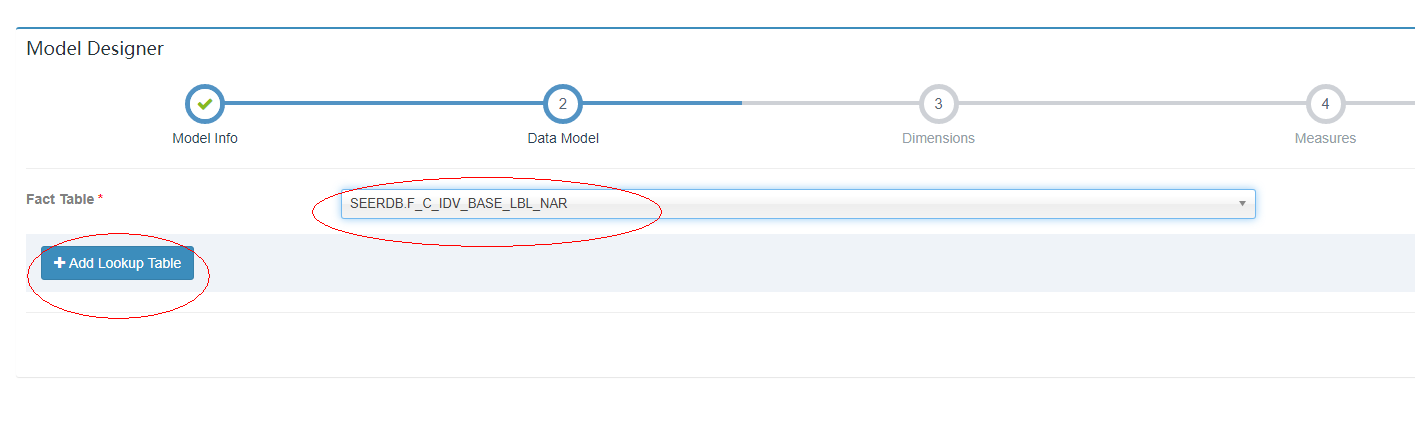 从下拉框选择事实表,如果有需要关联则点击 add lookup table添加关联表
从下拉框选择事实表,如果有需要关联则点击 add lookup table添加关联表
3.2.1.4 选择维度信息
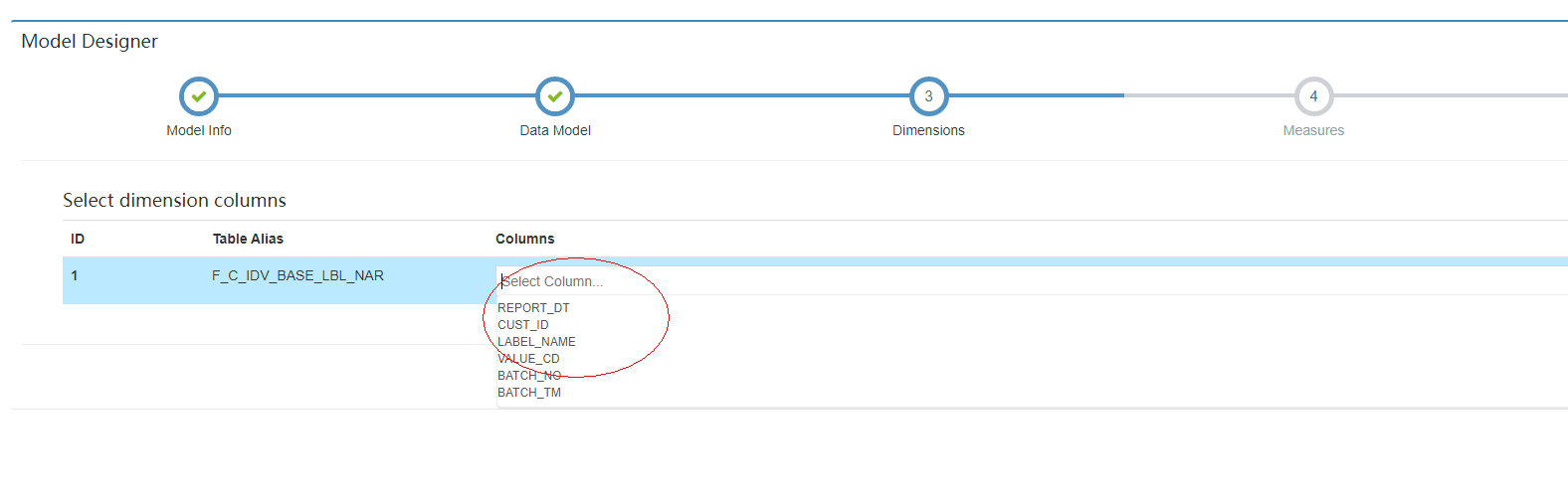 选择Report_dt,value_cd,lable_name,因为查询SQL需要根据这3个条件过滤。
选择Report_dt,value_cd,lable_name,因为查询SQL需要根据这3个条件过滤。
3.2.1.5 选择度量信息
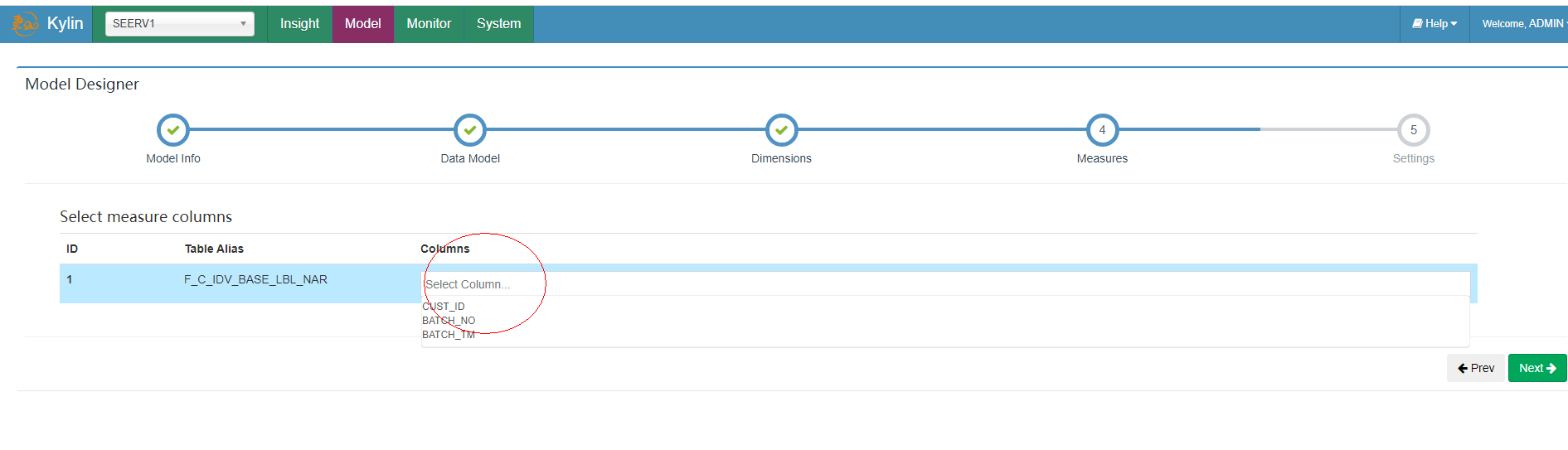 选择Cust_id,因为SQL需要统计这个的结果。
选择Cust_id,因为SQL需要统计这个的结果。
3.2.1.6 设置
 保持默认
保持默认
3.2.1.6 创建完成
3.2.2 创建cube
3.2.2.1 new cube
选择project->点击model->点击new->new cube
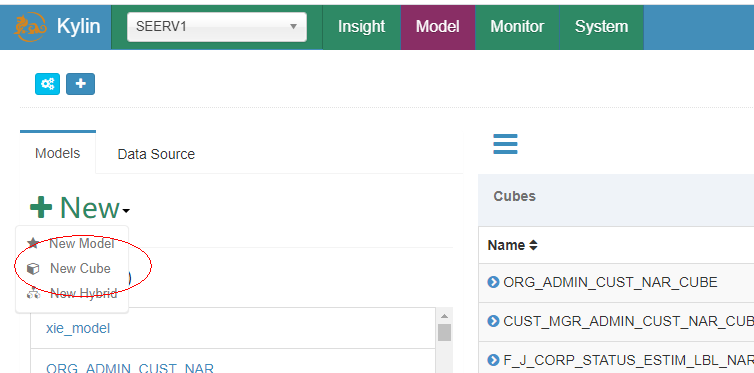
3.2.2.2 填写cube_info
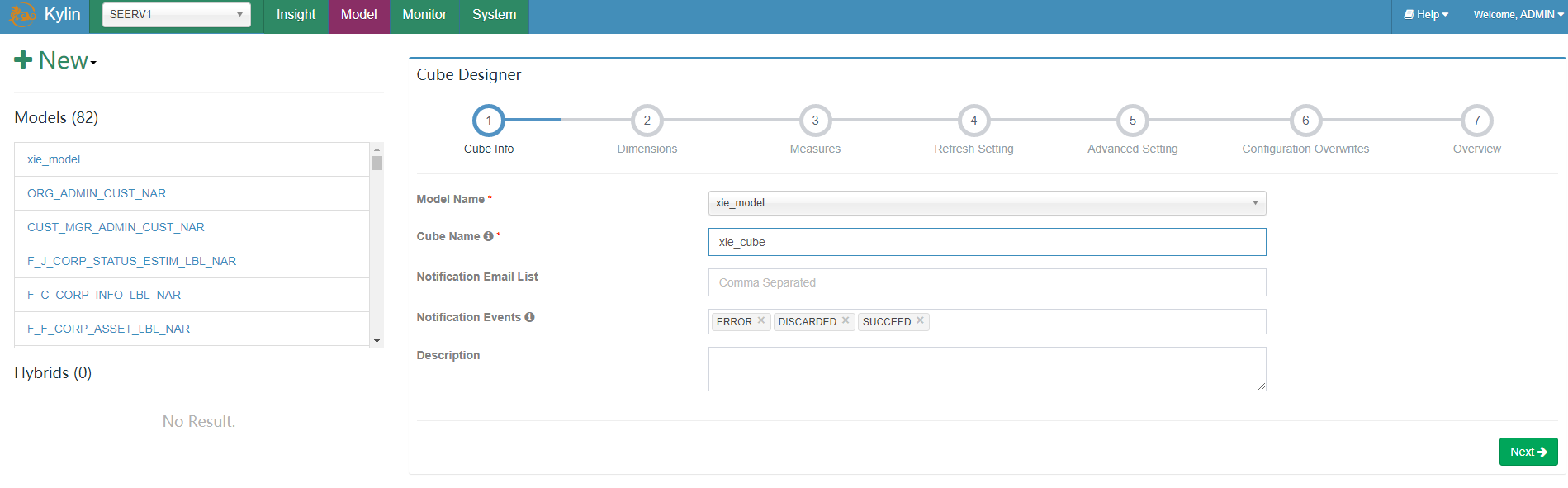 Model name选择刚才创建的model,输入cube name,其它默认。
Model name选择刚才创建的model,输入cube name,其它默认。
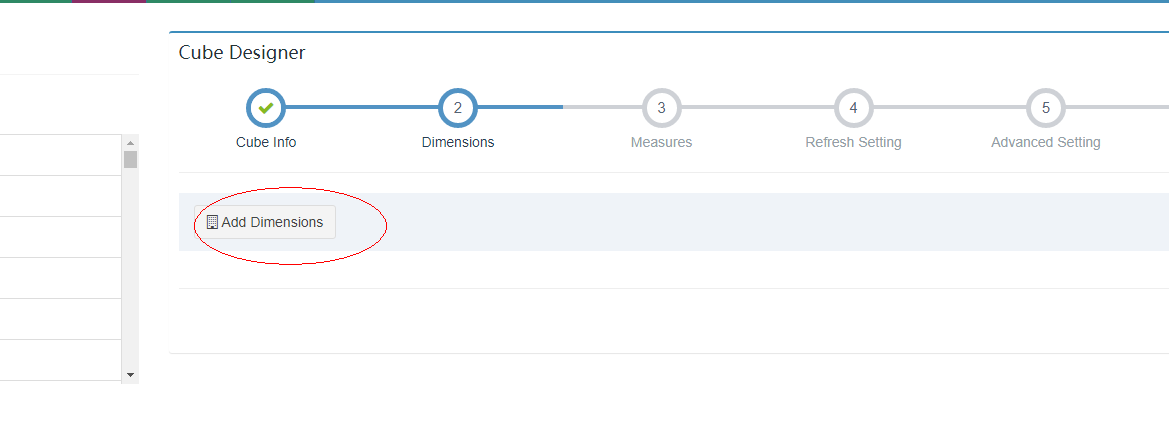
3.2.2.3 添加维度值
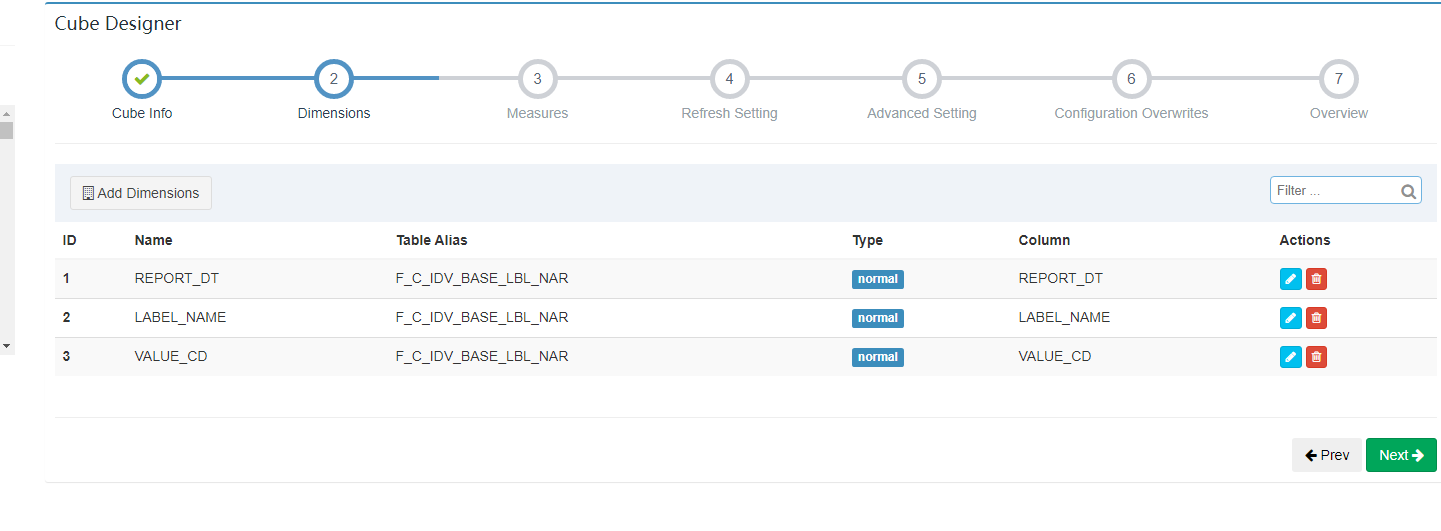
 真正的维度字段,将来会影响 Cuboid 的个数,并且只能从 model 维度字段里面选择。
真正的维度字段,将来会影响 Cuboid 的个数,并且只能从 model 维度字段里面选择。
3.2.2.4 添加度量值
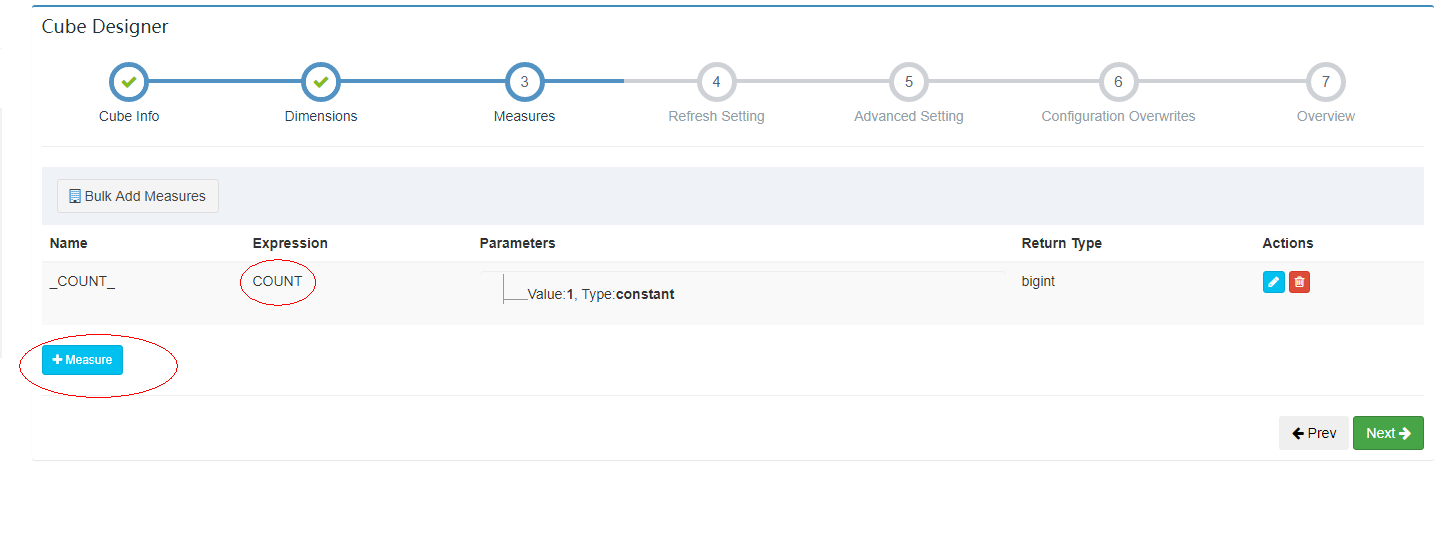
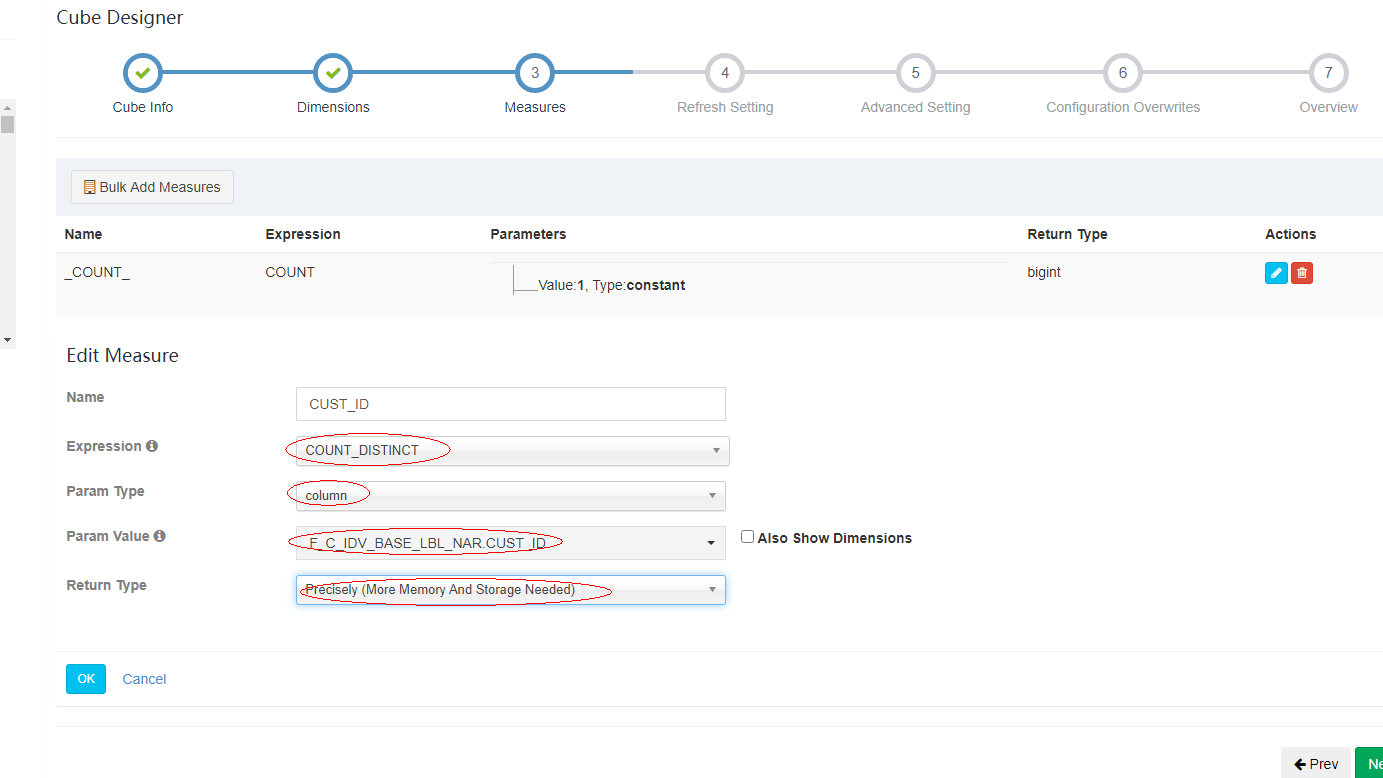 真正度量值字段,将来预计算的字段值,只能从 model 度量值里面选择。
真正度量值字段,将来预计算的字段值,只能从 model 度量值里面选择。
3.2.2.5 更新设置
 使用默认
使用默认
3.2.2.6 高级设置
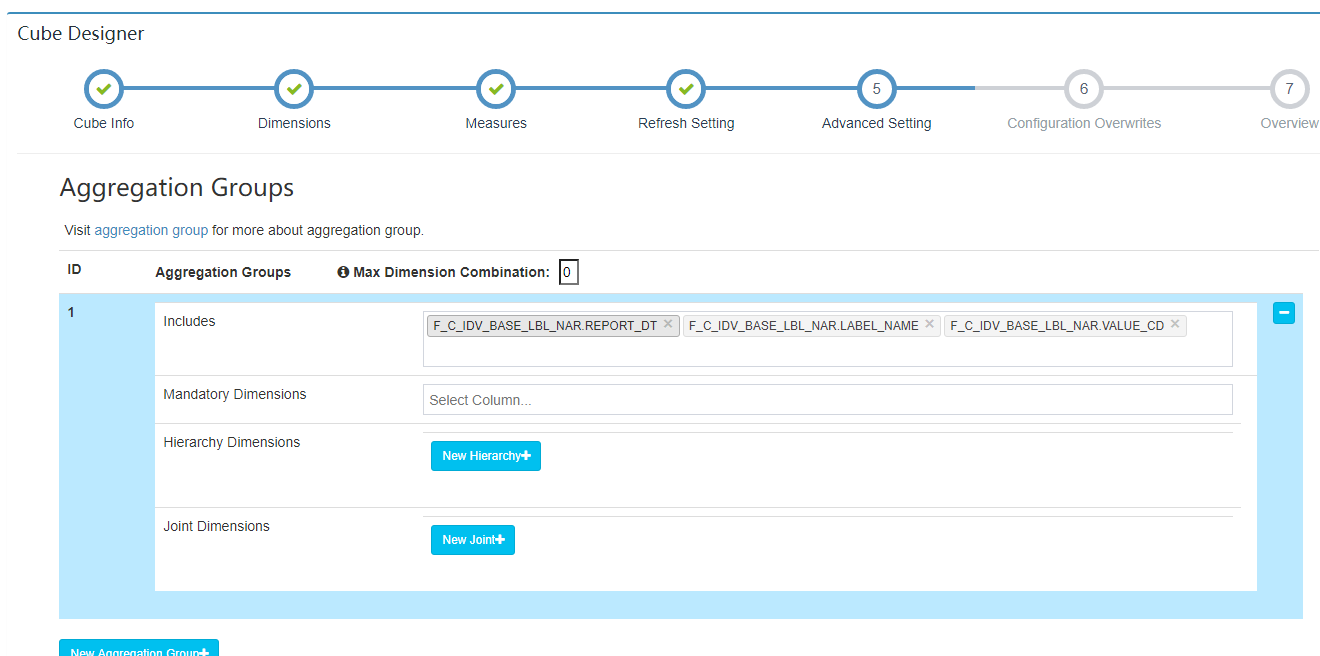 使用默认
使用默认
3.2.2.7 调整的kylin属性配置
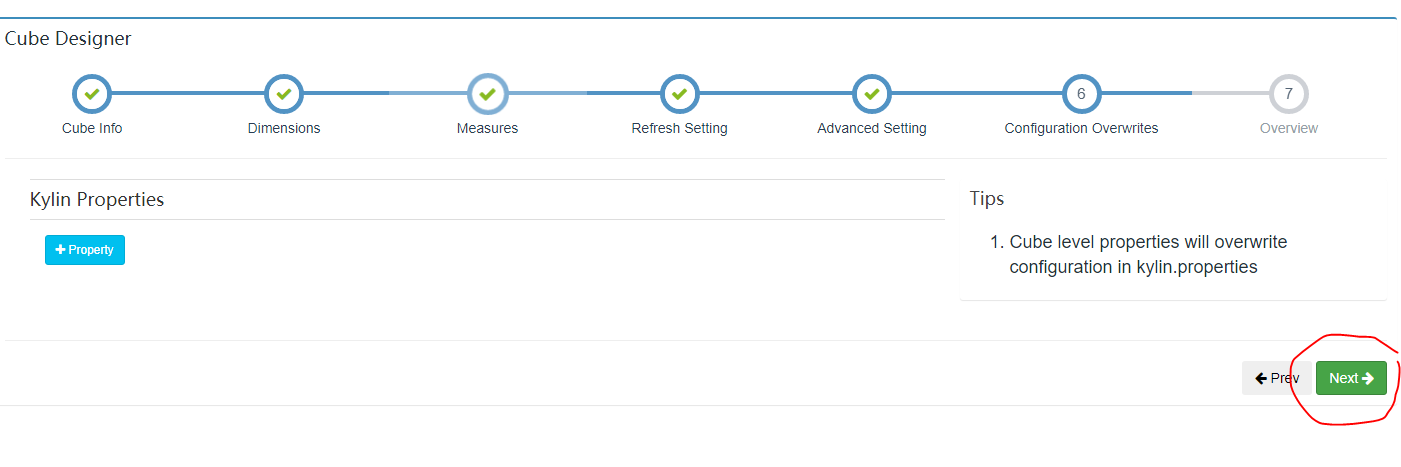 使用默认
使用默认
3.2.2.8 cube信息展示
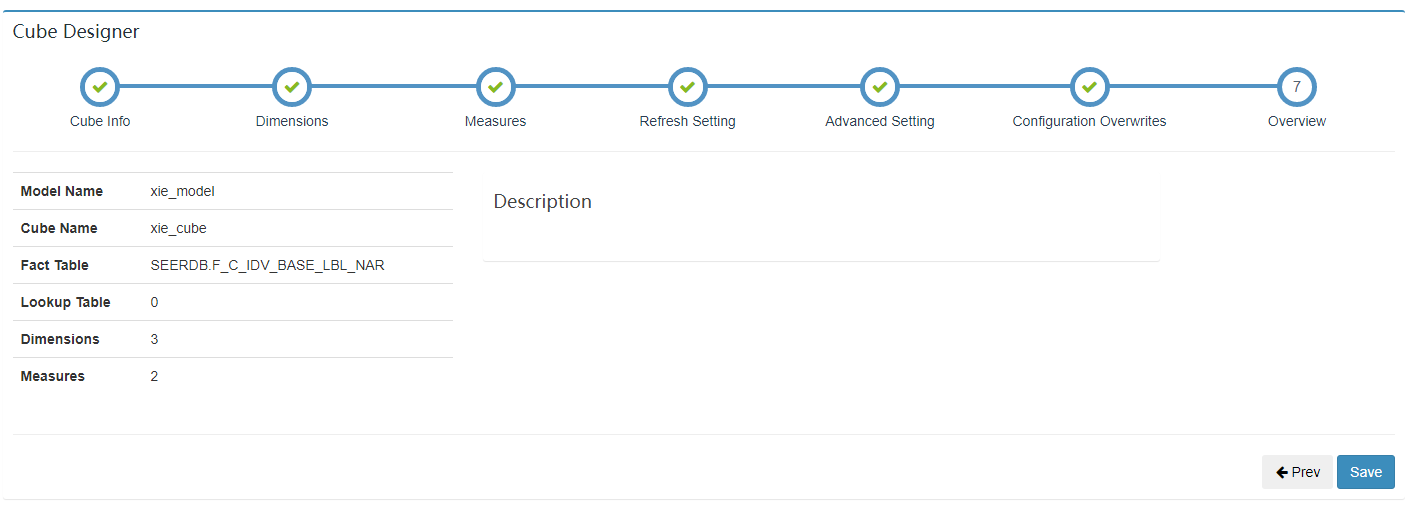
3.2.2.9 点击save完成

3.2.3 构建cube
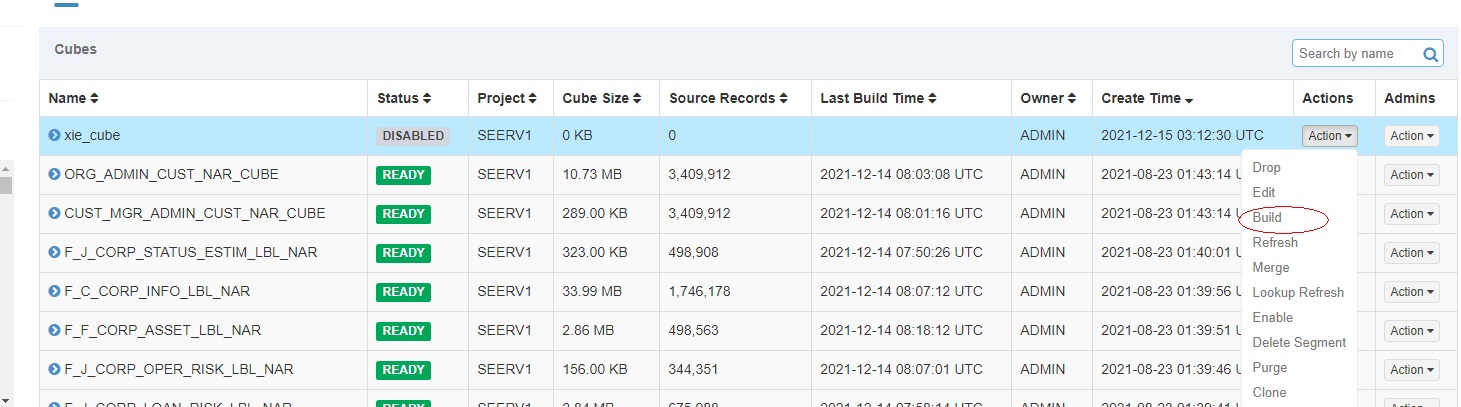
3.2.3.1 开始build
选中cube->点击action->点击build
3.2.3.2 查看构建信息
点击monitor
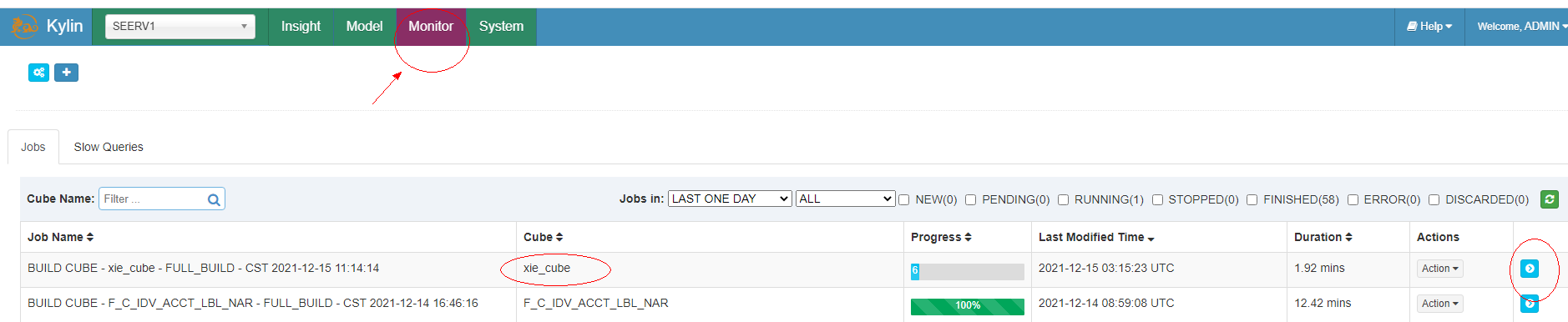 Duration构建时长,process构建进度(百分比)
Duration构建时长,process构建进度(百分比)
3.2.3.2 查看构建详情
点击上图中蓝色箭头查看
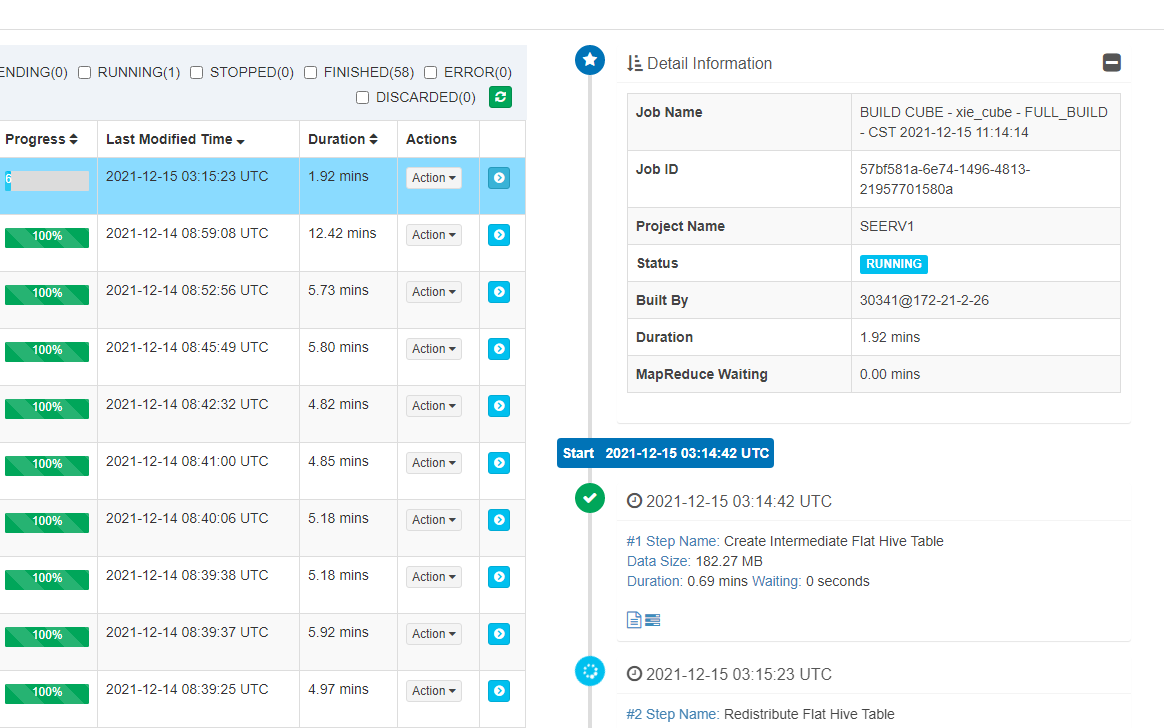
3.2.3.3 构建完成

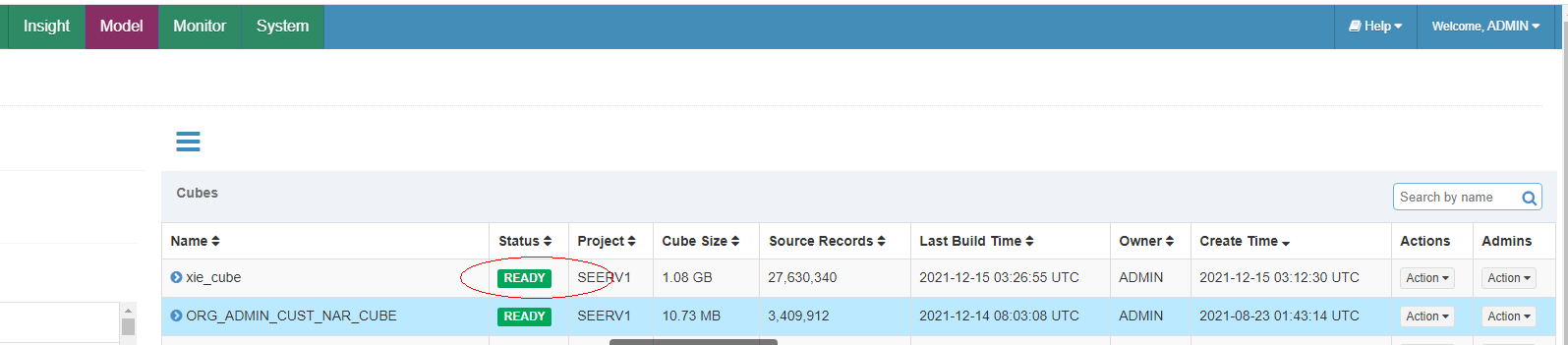 Status变为ready
Status变为ready
3.3. 注意事项
3.3.1 注意1
只能按照构建 Model 的连接条件来写 SQL。比如:在创建 Model 的时候,如果两张表之间选用的是 Inner Join 内连接, 在使用 Kylin 查询的时候,也只能用 join 内连接,其他连接会报错。并且还有一个要求就是顺序必须是事实表在前,维度表在后,否则报错!
3.3.2 注意2
只能按照构建 Cube 时选择的维度字段分组统计。比如:我们在构建 Cube 时,选择了四个维度字段 JOB,MGR,DEPTNO,DNAME,所以我们在使用 Kylin 查询的时候, 只能按照这四个为的字段进行 Group By 分组统计,使用其他字段,一定会报错!
3.3.3 注意3
只能统计构建 Cube 时选择的度量值字段。比如构建 Cube 时,只添加了一个 SUM(SAL)的度量值,然后加上默认的 COUNT(*),一 共有两个度量值,因此我们只可以利用 Kylin 求这两个度量值,求其他报错。
3.每日自动构建CUBE
Kylin 提供了 Restful API,因次我们可以将构建 cube 的命令写到脚本中,以实现定时调度的功能。
kylin_build_cube.sh
#!/bin/bash
PASSWD=KYLIN
USER=ADMIN
KYLIN_SERVER=http://hadoop102:7070/kylin
project_name=myProject
#授权信息
BASE64=`python -c "import base64; print base64.standard_b64encode('$USER:$PASSWD')"`
#从第 1 个参数获取 cube_name
cube_name=$1
#从第 2 个参数获取构建 cube 时间
if [ -n "$2" ]
then
do_date=$2
else
do_date=`date -d '-1 day' +%F`
fi
#获取执行时间的 00:00:00 时间戳(0 时区)
start_date_unix=`date -d "$do_date 08:00:00" +%s`
#秒级时间戳变毫秒级
start_date=$(($start_date_unix*1000))
#获取执行时间的 24:00 的时间戳
stop_date=$(($start_date+86400000))
CUBE_JOBS_NUM=`curl -s -X GET -H "Authorization: Basic $BASE64" $KYLIN_SERVER/api/jobs?projectName=$project_name\&cubeName=$cube_name\&timeFilter=0 | jq '.[] | {status: .job_status}' | grep -E "NEW|PENDING|RUNNING|STOPPED|ERROR|DISCARDED" | wc -l`
if [ $CUBE_JOBS_NUM -gt 0 ]; then
echo -e "Cube [$cube_name] is beeing built, please check its status or logs on the Monitor of Kylin..."
exit 1001
fi
echo -e "Building Cube[$cube_name] ..."
#发送请求
JSON=`curl -s -X PUT -H "Authorization: Basic $BASE64" -H "Content-Type: application/json" -d '{"startTime":'$start_date', "endTime":'$stop_date', "buildType":"BUILD"}' $KYLIN_SERVER/api/cubes/$cube_name/build | jq '. | {uuid: .uuid, name: .name, status: .job_status, progress: .progress, msg: .msg, stacktrace: .stacktrace, code: .code}'`
UUID=`echo $JSON | jq '. | .uuid'`
#处理请求结果
if [ $UUID != 'null' ]; then
PROGRESS=`echo $JSON | jq '. | .progress'`
echo "Building Cube[$cube_name],UUID[$UUID]"
printf "Progress:" $PROGRESS
#循环检查状态到结束
checkJobStatus $UUID
else
MSG=`echo $JSON | jq '. | .msg'`
if [ -z $MSG ] || [ $MSG = "null" ] || [ $MSG = "NULL" ]; then
echo "Cube[$cube_name] not exist."
exit 1002
else
echo $MSG
exit 1003
fi
fi
注:我们没有修改 kylin 的时区,因此 kylin 内部只识别 0 时区的时间,0 时区的 0 点是 东 8 区的早上 8 点,因此在脚本里要写$do_date 08:00:00 来弥补时差问题。
function checkJobStatus() {
#60s检查一次
WAIT_SEC=60
#参数传入
UUID=$1
UUID=${UUID//\"/}
JSON=`curl -s -X GET -H "Authorization: Basic $BASE64" $KYLIN_SERVER/api/jobs/$UUID | jq '. | {uuid: .uuid, name: .name, status: .job_status, progress: .progress, duration: .duration}'`
#运行时间
DURATION=`echo $JSON | jq '. | .duration'`
#状态
STATUS=`echo $JSON | jq '. | .status'`
STATUS=${STATUS//\"/}
if [ $STATUS == "NEW" ] || [ $STATUS == "PENDING" ] || [ $STATUS == "RUNNING" ]; then
# Wait $WAIT_SEC seconds and retry again...
PROGRESS=`echo $JSON | jq '. | .progress'`
printf $PROGRESS
sleep $WAIT_SEC && \
#构建时间超过一个小时,重新构建
if [ $DURATION -gt 3600 ]
then
echo ""
echo "job [ $cube_name ] duration: [ $DURATION ] will be droped and rebuilded"
# pause job
JSON_PAUSE=$(curl -X PUT -H "Authorization: Basic $BASE64" $KYLIN_SERVER/api/jobs/$UUID/resume)
# discard job
JSON_DISCARD=$(curl -X PUT -H "Authorization: Basic $BASE64" $KYLIN_SERVER/api/jobs/$UUID/cancel)
# drop job
JSON_DROP=$(curl -X DELETE -H "Authorization: Basic $BASE64" $KYLIN_SERVER/api/jobs/$UUID/drop)
# rebuild job
//todo 重新调用构建job
else
checkJobStatus $UUID
fi
else
if [ $STATUS == "FINISHED" ]; then
printf '\b%6.1f%%' 100
echo -e "\nBuilding Cube [$cube_name] success!"
exit 1000
else
if [ $STATUS == "STOPPED" ]; then
printf 'job STOPPED'
#等待再试
sleep $WAIT_SEC && \
checkJobStatus $UUID
else
echo -e "\nBuilding Cube [$cube_name] failed with status: $STATUS"
exit 1004
fi
fi
fi
}




